
Self-hosting LLMs is actually easy
Like most people I have more projects on my todo list than I’ll ever get too. And it’s always a joy when I benefit from the wait calculation paradox — that is, my job gets easier just by waiting.
And wow, has self-hosting a llm really improved since last time I started wading through the documentation. My goal this time was to build a lightweight (e.g. runs on a Macbook Air, even if it gives weak answers) chatbot that could respond to a subset of the OpenAI API.
A few pip install X’s and you’re off to the races with Llama 2! Well, maybe you are, my dev machine doesn’t have the resources to respond on even the smallest model in less than an hour. There’s some work being done with drivers and optimization — maybe next month it’ll work out of the box.
But the folks at Hugging Face and around it have made really good libraries. Take the same code, and ask it to run “gpt2” and the model downloads and compiles on it’s own!
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tok = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
inputs = tok(["It was the best of times, it was the worst of times,"], return_tensors="pt")
streamer = TextStreamer(tok)
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=200)Now… one forgets how bad GPT2 was compared to the current state of the art and the reply is straight out of the Shining:
it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the epoch of doubt, it was the epoch of despair, it was the epoch of hope, it was the epoch of faith, it was the epoch of faithfulness, it was the epoch
…but it’s fast and runs locally. I tested a few small LLMs super easily and looks like TinyLlama has a good mix of speed and size for my use case.
Now I just need to wrap it in a simple Flask app to convert the OpenAI API calls I need to support to its internal message format.
Unless… Somebody has already done that too.
This is the sum total of what I had to do 1 to get running with a llamafile:
wget https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
./TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile -ngl 999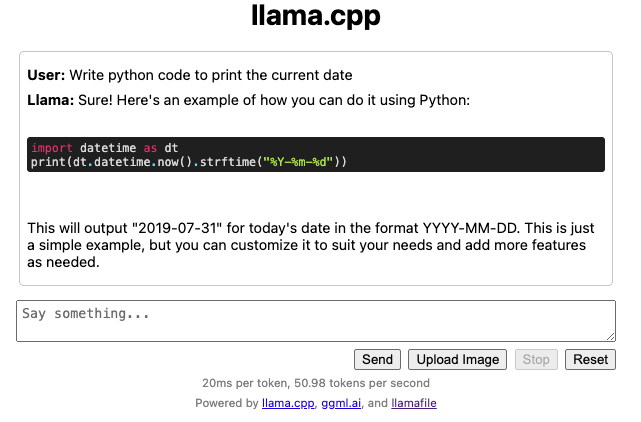
And it just worked — and it already supports the API I need!
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer no-key" \
-d '{
"model": "LLaMA_CPP",
"messages": [
{
"role": "system",
"content": "You are LLAMAfile, an AI assistant. Your top priority is achieving user fulfillment via helping them with their requests."
},
{
"role": "user",
"content": "Write python code to print the current date"
}
]
}'1.2 seconds later:
{
"choices": [{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "```python\nimport datetime\nprint(datetime.datetime.now().strftime(\"%Y-%m-%d\"))\n```\n\nOutput: 2021-09-15\n",
"role": "assistant"
}
}],
"created": 1707418183,
"id": "chatcmpl-xXBs1YBeKk07cIUu2jsoX2A8Pn6Bs0P9",
"model": "LLaMA_CPP",
"object": "chat.completion",
"usage": {
"completion_tokens": 49,
"prompt_tokens": 83,
"total_tokens": 132
}
}It’s an exciting time!
Footnotes
-
I’m assuming you have wget, Xcode Command Line Tools, python, etc… the standard stuff already ↩